事情起源于log的一段报错 ERROR: could not serialize access due to concurrent update,有经验的开发人员都知道是并发错误,一般都会在应用层去做一些补偿机制处理。但也有人问Odoo本身自带了retry机制去自动重试5次,下面也出现相应的log,为什么好像没有执行?这时发现我们虽然一直在用ORM和PostgreSQL数据库,但是却对内部的原理,机制不了解,所以带着疑问去了解下pg数据库事务相关概念,以及Odoo是怎么处理的。
结论
由于后面主要是讲解概念相关,所以开头讲出结论,后面内容部分读者可按自己需要自行选读.
- PG数据库事务隔离级别实现的比标准SQL更严格
- PG数据库默认是用 读已提交 隔离级别,
Odoo没有修改数据库的隔离级别,但是内部有处理,都是以 可重复读 隔离级别开启事务 Odoo有自己的简单重试5次机制,每次重试都会清理上下文,并重新创建事务.
数据库基础知识
为了更好的介绍,先简单的说说数据库的几个基本概念,如果你对某些概念已熟悉,可以跳过对应部分。
事务(Transaction)
我们所用的orm一系列操作,最终都会转化成对应的sql语句和事务中去执行,那么,什么叫事务呢?下面给出定义和示例。
SQL中的事务是一系列操作的集合,具有ACID的特性,我们接下来主要介绍的是A指的是原子性(Atomicity), I指的是隔离性(Isolation)。
原子性指的是一个事务中的所有操作,要么全部成功、要么全部失败。
这些操作被视为单个逻辑单元,必须全部执行或全部回滚。在SQL中,事务是用于确保数据一致性和完整性的重要机制。
在SQL中,事务通常由以下四个操作构成:
- 开始(BEGIN):事务的开始标记。
- 执行(COMMIT):将所有操作提交到数据库,如果所有操作都成功,则将更改永久保存。
- 回滚(ROLLBACK):撤消事务中的所有更改,并将数据库恢复到事务开始之前的状态。
- 保存点(SAVEPOINT):用于将事务划分为多个子事务,可以在不影响整个事务的情况下回滚某些更改。 事务可以保证数据库的一致性和完整性,因为如果在事务中出现错误,所有更改都将被回滚到事务开始之前的状态。这可以确保数据库始终保持在一致的状态,并且不会发生意外的数据损坏。
以下是一个简单的SQL事务示例,假设有一个银行账户表,包含账户余额的信息:
|
|
在上述示例中,我们使用BEGIN语句开始一个事务,然后使用UPDATE语句执行两个操作,将100元从账户A转移到账户B。接下来,我们使用IF语句检查转账是否成功,如果失败,则使用ROLLBACK语句回滚事务,否则使用COMMIT语句提交更改。如果我们执行了ROLLBACK语句,则所有更改都将被撤销,否则,所有更改都将被永久保存到数据库中。
并发控制 (Concurrency Control)
并发控制是多个事务在并发运行时,数据库保证事务一致性(Consistency)和隔离性(Isolation)的一种机制。主流商用关系数据库使用的并发控制技术主要有三种:严格两阶段封锁(S2PL)、多版本并发控制(MVCC)和乐观并发控制(OCC)。
PostgreSQL使用了多版本并发控制技术的一种变体:快照隔离Sanpshot Isolation(简称SI)。
PostgreSQL的事务隔离(Transaction Isolation)
sql把多个并发事务之间可能发生的交互作用和影响称为现象(Phenomena), sql定义了这几种可能发生的现象:
-
脏读(Dirty Read):一个事务可以读取另一个并发事务尚未提交的未经提交的数据。如果尚未提交的事务被回滚,则读取的数据将是无效的。
-
不可重复读(Non-repeatable Read):在同一事务中,两次读取相同的行返回不同的结果。这可能是由于另一个并发事务提交了更改,也可能是由于事务自身提交了更改。
-
幻读(Phantom Read):在同一事务中,两次读取相同的查询返回不同的结果集。这可能是由于另一个并发事务提交了新的行,也可能是由于事务自身提交了新的行。
-
串行化异常(Serialization Anomaly):事务并发执行时,可能会出现一些不正确的结果,这些结果不符合事务串行执行时的一致性。这包括脏写(Dirty Write)和读写冲突(Read-Write Conflict)。
SQL标准定义了四个事务隔离级别, 分别是:读未提交(Read Uncommitted),读已提交(Read Committed),可重复读(Repeatable Read),序列化(Serializable)。在每个级别中都有不能发生的现象, 比如最严格的是序列化,它保证任意并发执行的事务以某种顺序一个一个执行, 在这个级别时,上述所有现象都不会发生。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 序列化异常 |
|---|---|---|---|---|
| 读未提交 | 允许,但不在 PG 中 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 允许,但不在 PG 中 | 可能 |
| 可序列化 | 不可能 | 不可能 | 不可能 | 不可能 |
通过以上表格可以发现, PostgreSQL其实内部只实现了3种隔离级别,它的读未提交模式和读已提交是一样的,以及pg在可重复度级别里面实现的也比标准更严格,在该级别就禁止了幻读现象.
补充: 在PostgreSQL 9.0或以下版本并没有可重复读隔离级别,在9.1之后,PostgreSQL实现了Serializable Snapshot Isolation(简称SSI),原隔离级别SERIALIZABLE变为新增的隔离级别REPEATABLE READ,新实现的SSI成为SERIALIZABLE, 此时才有4个级别。
读未提交, 读已提交
读已提交是PostgreSQL中的默认隔离级别, 在PG的文档中是这么描述的它的运作方式的.
When a transaction uses this isolation level, a SELECT query (without a FOR UPDATE/SHARE clause) sees only data committed before the query began; it never sees either uncommitted data or changes committed during query execution by concurrent transactions. In effect, a SELECT query sees a snapshot of the database as of the instant the query begins to run. However, SELECT does see the effects of previous updates executed within its own transaction, even though they are not yet committed.
以上这段简单的说就是在此级别上, 执行一个SELECT(不带FOR UPDATE/SHARE)命令, 它只能查询到SELECT执行瞬间除自身事务以外数据库所有已提交数据的快照, 自身事务的改动且没提交的数据还是可以看到的.
根据此说法不难可以想到如果有事务T1和事务T2, T1执行了一次查询得到结果Q1, 然后T2则更新相关数据后提交,此时T1再执行一次查询,得到Q2, 这是可以Q1和Q2的结果是不一样的,这就造成了不可重复读的问题. 也就是说相同命令执行了俩次,但是看到的结果可能不一样.
可重复读隔离级别
可重复读隔离级别是在PG 9.0之后的版本引入的, 它和读已提交之间有两个明显的区别:
- 提供了一致性读, 在事务启时,生成一个当前数据的快照,后续所有数据都是从这里查询. 这样就避免了不可重复读的问题, 因为在事务开始后, 即使其他事务提交/修改了数据也不会影响本次事务的查询.
- 并发事务写操作
(UPDATE, DELETE, MERGE, SELECT FOR UPDATE, and SELECT FOR SHARE)设计数据冲突的处理不同.
在读已提交时级别时, 两个都会执行,只是会有一个先后顺序. 如果有一个T1事务在对数据写操作, T2要写相同数据时就要等T1完成(等待获取写锁), 然后先后都会执行成功.
在可重复读级别时, 两个事务涉及写同一个数据时会发生冲突,那么其中之一会回滚.PG用FUW协议来去处理事务之间的冲突
出现冲突时,冲突处理常用的协议包括FCW(First Commit Wins,先提交者胜)和FUW(First Updater Wins,先更新者胜)。
FCW:事务Ti准备提交时,检查是否存在其他已提交的事务变更了数据对象x,如存在则回滚,否则提交
FUW:如事务Tj已持有数据对象x的锁,同时Ti希望变更x,则Ti必须等待直至Tj提交或回滚;如Tj提交,则Ti回滚,如Tj回滚,则Ti可以获取x的写锁,事务继续执行。
失败的一方事务会带着以下消息回滚: ERROR: could not serialize access due to concurrent update.
可序列化隔离级别
可序列化隔离级别提供了最严格的事务隔离。这个级别为所有已提交事务模拟序列事务执行;就好像事务被按照序列一个接着另一个被执行,而不是并行地被执行。
读者可能会困惑,在可重复度读级别上就已经做到禁止幻读了,还可能有哪些问题? 实际上不可串行化的事务的可能存在写倾斜(Write Skew)现象.
一个经典的例子,现有数据表doctor,业务约束要求处于oncall状态(oncall值为true)的医生人数不能少于1人,老王和老张说两位值班医生,碰巧都身体不适决定请假。他们几乎同一时刻点击了调班按钮,接下来的事情如下图所示。
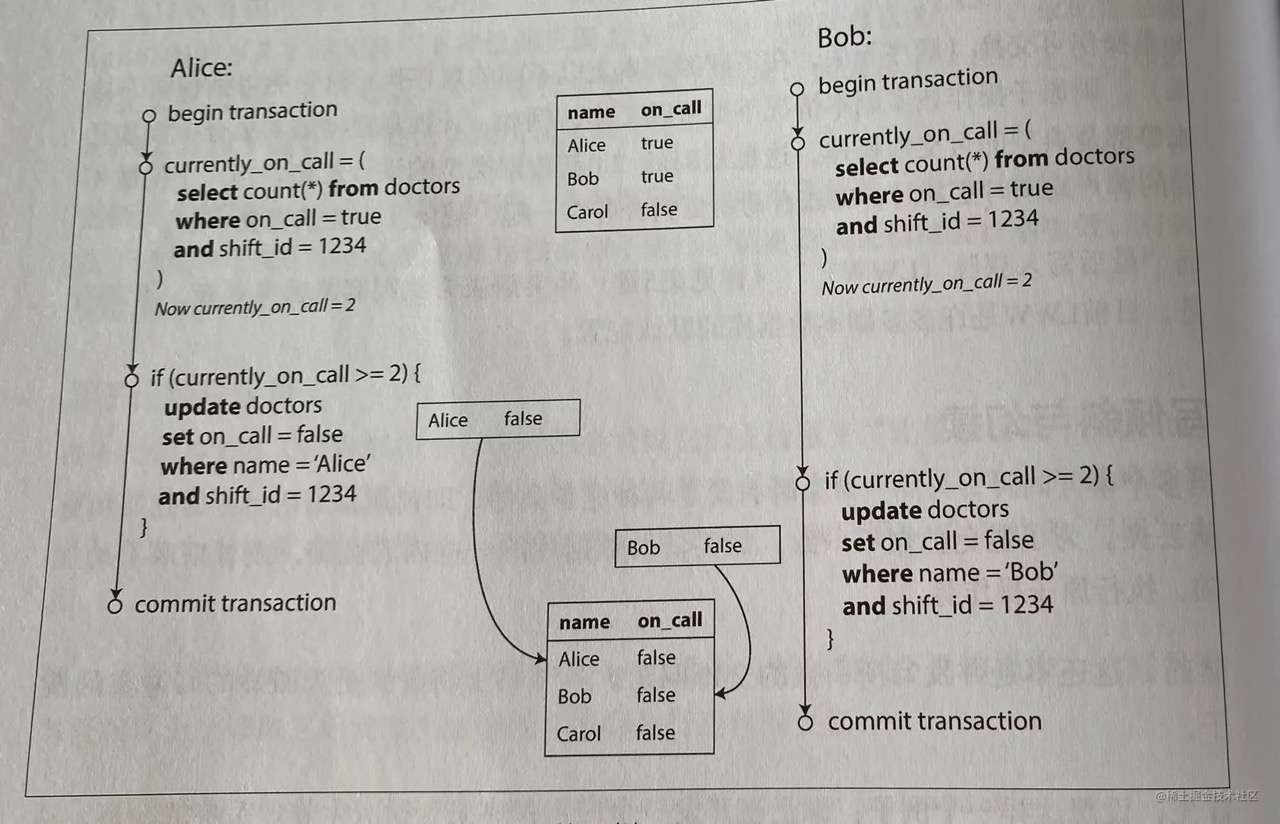
每个事务总是首先检查是否至少有两个医生在值班,如果是,则当前的医生可以安全的离开。这里使用快照隔离级别,但是上面这种场景下,这两个医生都成功提交,都可以正常休假,最终是没有任何医生在值班了。
这种情况称为写倾斜,两个事务更新的是不同的对象,写冲突看起来不那么直接,但是在这里,两个事务读取相同的一组对象,然后更新其中一部分,不同的事务可能更新不同的对象,则可能发生写倾斜。最终是违背了业务逻辑。
针对这种情况, 数据库中只有可序列化隔离级别才能解决这个问题.和可重复读类似的,如果事务失败,会提示
ERROR: could not serialize access due to read/write dependencies among transactions
小结
到这里为止,我介绍了数据库中的事务相关概念,还有并发事务之间冲突可能产生的问题,相信读者已初步了解PG数据库的事务了.从几个级别的现象我们可以得知Odoo中应该是用可重复读隔离级别来处理应用的, ,但是PG数据库用show default_transaction_isolation;来查询隔离级别时,却显示用的是读已提交,这说明Odoo框架内部应该是做了一些操作设置, 接下来我们就到Odoo源码里面一探究竟.
Odoo的设置
事务隔离级别
Odoo的ORM框架分层做的很好, 涉及数据库的一些设置,在sql_db.py的autocommit方法中找到了答案.
|
|
这段代码以及注释表明了把每一个数据库游标的隔离级别都设置成REPEATABLE_READ. 同时也指明出一个小坑: psycopg在2.4.2之前的版本,都是内部处理把可重复读映射到可序列化(前文有提到,在9.1之前的版本PG只有3个隔离级别之前的序列化等于9.1及之后版本的可重复读). 所以在2.4.2之前版本和pg 9.1版本一起用时会有坑, 这是需要注意的一个点.
代码部分再往上点到Cursor这个类是Odoo游标的实现类,里面有很长的一段文档,详细的讲解了Odoo是怎么考虑的,为什么最后选择REPEATABLE READ作为框架默认数据库级别. 篇幅有限就不在这展开,有兴趣的读者可以到源码里面查看. 这段文中还有一段关键信息:
OpenERP implements its own level of locking protection for transactions that are highly likely to provoke concurrent updates, such as stock reservations or document sequences updates.
Therefore we mostly care about the properties of snapshot isolation, but we don’t really need additional heuristics to trigger transaction rollbacks, as we are taking care of triggering instant rollbacks ourselves when it matters (and we can save the additional performance hit of these heuristics).
这段文字有两段关键信息:
Odoo对于库存预留,文档更新等并发更新产生频繁的功能,实现的代码中有相关处理.Odoo有利用PG的RR隔离级别特性,来做事务的回滚操作.
对于信息2, 我们可以联想到开头的那段报错,以及之前提到,PG在RR级别事务失败时产生的错误信息,都是一样的,也就是说Odoo应该是主动捕获PG失败时会产生的异常来做回滚,相关的处理.既然有了相关思路,那也不难去找Odoo的内部实现了.
事务的回滚和重试
带着前面的思路可以定位到model.py中check方法,这里有很关键的一段:
|
|
这段我们可以看到每当出PG_CONCURRENCY_ERRORS_TO_RETRY异常时,Odoo会帮我们重试5次, 其中这个变量的定义如下:
|
|
所以当Odoo执行事务时,每当碰到数据库报错提示 锁不可用,事务冲突,检测死锁,导致事务失败时,会主动的去重新尝试执行,这是一个自带简单但可靠的机制.
同时,我们也可以注意到这是一个装饰器函数,这意味着一般某个入口函数会调用它,在http.py的函数中337行找到了对应的入口
|
|
开头的注释表明Odoo处理请求时确实有意识的去实现重试机制, 以及第二段注释表名,如果事务失败时,Odoo会主动回滚事务,并重新去创建事务执行.
这里也同时发现了一个小坑:
开头有人提到为什么retry打了log,却好像没执行,后面根据此看逻辑,发现其实是因为self.env.clear()这一句,导致了客户端context(上下文)被清掉了,而那段代码又依赖context去执行,就导致了虽然运行,但是没达到预期效果.
相关资料参考
至此需要了解的概念已经介绍完了,篇幅有限无法针对每个具体的点详细展开,实际上这些概念内部还有更多的细节,有兴趣的可以去参阅.